 Arte Moderni 기술블로그
Arte Moderni 기술블로그
Kafka Cluster
Kafka Cluster란?
인사
안녕하세요 F4팀의 김혁준입니다. Kafka를 활용한 프로젝트를 구현하면서 Kakfa에 대해 제가 이해한 점을 정리하고 공유하기 위해 글을 작성합니다. 부족한 부분이 있을 수 있으니 가볍게 참고용으로 봐주시길 바랍니다😊
Kafka Cluster
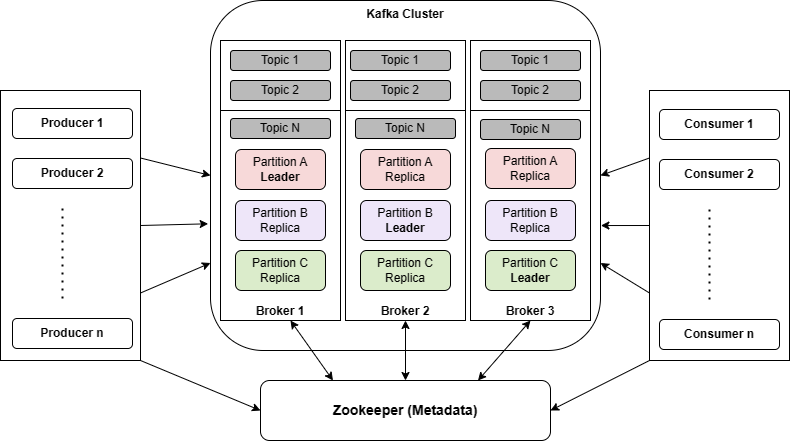
출처 : https://howtodoinjava.com/kafka/kafka-cluster-setup-using-docker-compose/
카프카 클러스터는 스케일 아웃 기반으로 노드 증설을 통해 카프카의 메시지 전송과 읽기 성능을 거의 선형적으로 증가시키고
데이터 복제를 통해 분산 시스템 기반에서 카프카의 최적 가용성을 보장합니다.
멀티 노드, Replication
분산 시스템은 대량 데이터를 여러 노드간 분산 처리를 통해 빠르게 처리할 수 있는 큰 성능적 이점을 가지지만 안정성과 가용성 측면에서 상대적인 단점을 가집니다.
카프카를 단일 노드로 사용한다면 단일 노드에 대해서만 가용성 구성을 강화하면 되므로 매우 안정적인 시스템 구성이 가능하고 소프트웨어에서 다양한 성능 향상 기법을 도입하기 쉽지만
단일 노드에서 처리하려는 데이터가 기하 급수적으로 늘어난다면 scale up 방식으로 증설하기에는 한계가 있습니다.
멀티 노드
다수의 노드에서 분산 구성 시 개별 노드를 scale out 방식으로 증설하여 한 개의 노드에서만 장애가 발생해도 올바른 데이터 처리가 되지 않고 다수의 하드웨어로 구성하므로 빈번한 장애 가능성, 관리 부담이 증가합니다.
또한, 소프트웨어 자체에서 성능, 가용성 처리에 제약이 생깁니다.
이러한 문제를 데이터 복제를 통해 분산 시스템 기반에서 카프카의 최적 가용성 보장
카프카 Replication
개별 노드의 장애를 대비하여 높은 가용성을 제공합니다. 가용성의 핵심은 Replication
토픽 생성 시 replication factor를 설정하는데 reflication factor가 3이면 원본 파티션과 복제 파티션을 포함하여 모두 3개의 파티션을 가짐을 의미하고 replication factor의 개수는 브로커의 개수보다 클 수 없습니다.
replication의 동작은 토픽 내의 개별 파티션들을 대상으로 적용되고
replication factor의 대상인 파티션들은 1개의 leader와 n개의 follower로 구성됩니다.
producer와 consumer는 leader 파티션을 통해서 쓰기와 읽기 수행하고 파티션의 replication은 leader에서 follwer로만 이뤄집니다.
파티션 리더를 관리하는 브로커는 producer/consumer의 읽기/쓰기를 관리함과 동시에 파티션 팔로우를 관리하는 브로커의 replication도 관리합니다.

출처 : https://jack-vanlightly.com/blog/2018/9/2/rabbitmq-vs-kafka-part-6-fault-tolerance-and-high-availability-with-kafka
위 그림을 예로 들면 브로커 3개가 있는 kafka cluster에서 Partition이 4개, Replication factor가 3인 토픽이 있을 때
파티션 0의 leader가 브로커 2에 있으므로 브로커 1,3에 있는 파티션 0(follower)은 브로커 2의 파티션 0을 복제합니다.
다른 파티션들도 마찬가지로 follower가 leader를 복제하여
각각의 브로커에 모든 파티션들이 존재하게 되고 한 브로커에 문제가 생겨도 데이터를 안정적으로 처리할 수 있습니다.
ISR : In-Sync-Replicas
동기화 되어있는 브로커라고 생각하면 편할것 같습니다.
follower 중 isr 내에 있는 follower들만 리더가 될 수 있습니다.
파티션의 leader 브로커는 follwer파티션의 브로커들이 leader가 될 수 있는지 지속적으로 모니터링을 수행하여 isr을 관리합니다.
leader 파티션의 메시지를 follower가 빠르게 복제하지 못하고 뒤쳐질 경우 isr에서 해당 follower는 제거되며 해당 파티션은 leader가 문제가 생길 때 leader가 될 수 없음
zookeeper.session.timeout.ms로 지정된 기간(기본 6초 최대 18초)내에 heart beat을 지속적으로 주키퍼에 보내야한다.
replica/lag/time/max/ms로 지정된 기간 (기본 10초, max 30초)내에 leader의 메시지를 지속적으로 가져가야한다.
leader 파티션이 있는 브로커는 follower들이 제대로 데이터를 가져가는지 모니터링 하면서 isr 관리
follower는 leader에게 fetch 요청을 수행, fetch 요청에는 follower가 다음에 읽을 메시지의 offset 번호를 포함 leader는 follower가 요청한 offset 번호와 현재 leader partition의 가장 최신 offset 번호를 비교하여 follower가 얼마나 leader 데이터 복제를 잘 수행하고 있는지 판단
isr에서 벗어난 브로커는 카프카 클러스터의 안정성을 위해 자동으로 다시 isr에 포함될 수 없습니다.
다시 복구시키려면 수동으로 설정 해줘야합니다.
정리
Kafka를 사용하여 엄청난 양의 데이터를 빠르게 처리하기 위해 멀티 노드 클러스터를 사용한다.
데이터의 손실을 방지하기 위해 Replication 사용한다.
데이터를 빠르게 처리하는 것도 좋지만 아무래도 데이터를 잃어버리지 않고 안정적으로 처리하는 것이 중요하기 때문에 단순히 브로커 여러개를 사용하는 것보다 replication을 활용해서 데이터의 안정성을 높이는 것이 중요한 것 같습니다.😁